Mejoras en los modelos meteorológicos
Actualmente se obtienen en una hora cientos de terabytes de datos provenientes de satélites remotos, radares meteorológicos, y otros numerosos instrumentos que miden el estado de la atmósfera.
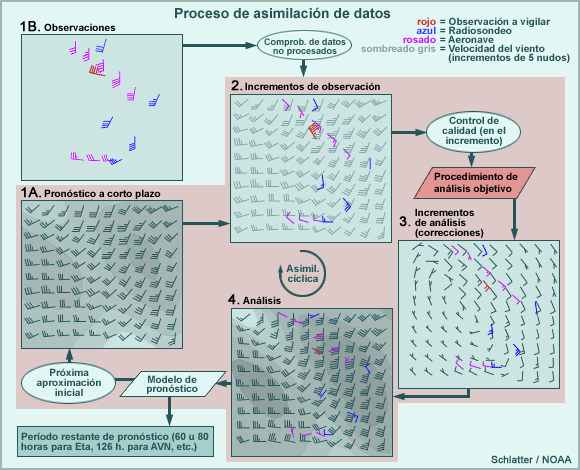
Con este caudal de información, los científicos se enfrentan al desafío de desarrollar técnicas para el análisis de “big data” destinadas, en este caso, a mejorar los pronósticos meteorológicos, pero fundamentalmente enfocadas en la prevención de desastres naturales. La utilización de toda esta información observacional en los pronósticos meteorológicos es lo que se denomina asimilación de datos.
El doctor Manuel Pulido, docente del Departamento de Física de la Facultad de Ciencias Exactas y Naturales y Agrimensura de la UNNE, e investigador en el Instituto de Modelado en Innovación Tecnológica del Conicet (Argentina), desarrolló, junto a su grupo de trabajo, una técnica basada en el aprendizaje automatizado “para inferir el error de modelo, en modelos de pronósticos meteorológicos”. Dicho de otra forma, la técnica permite seleccionar datos de toda la información circundante, de forma tal que se reduzca el error en los modelos de pronósticos meteorológicos.
Uno de los desafíos que presenta en la actualidad la asimilación de datos, explica Pulido, es la “estimación de la incerteza de modelos”. Y afirma: “En el grupo trabajamos hace ya cinco años en el desarrollo de una técnica que permita determinar la incerteza o error de un modelo matemático de pronósticos utilizando un conjunto de observaciones en un marco estadístico. El desarrollo está basado en lo que se denomina el algoritmo de Expectation-Maximization”. Los resultados de este trabajo fueron expuestos por Pulido en el mes de abril de 2018, en el International Symposium on Data Assimilation (ISDA2018), que se llevó a cabo en Munich, Alemania. En esa oportunidad, el físico argentino fue uno de los disertantes principales (keynote speaker) en el simposio científico.
Las técnicas sobre las que se enfocó la conferencia brindada por el Dr. Pulido están basadas en el “aprendizaje automatizado”. ¿En qué consiste este método?
“Son técnicas que en general trabajan mediante el aprendizaje asistido, es decir, utilizan una gran cantidad de datos para clasificar situaciones y luego, una vez que aprendidas, se pueden utilizar en nuevas circunstancias de la vida cotidiana”, explicó Pulido. En este sentido, son como la mente del ser humano: a través de múltiples observaciones son capaces de aprender situaciones, por mecanismos de prueba y error, las cuales luego son aplicadas con diversos fines.
El aprendizaje automatizado (machine learning) tuvo un fuerte desarrollo en las ciencias de la computación en los últimos años, en los que generó una gran revolución tecnológica. En esencia son técnicas del aprendizaje automatizado, aquellas que se utilizan para reconocimiento facial, interpretación de texto para los traductores, digitalización de textos hasta, incluso, las que se utilizan para los autos que se manejan sin conductores.
NCYT (Noticias de Ciencia y Tecnología)